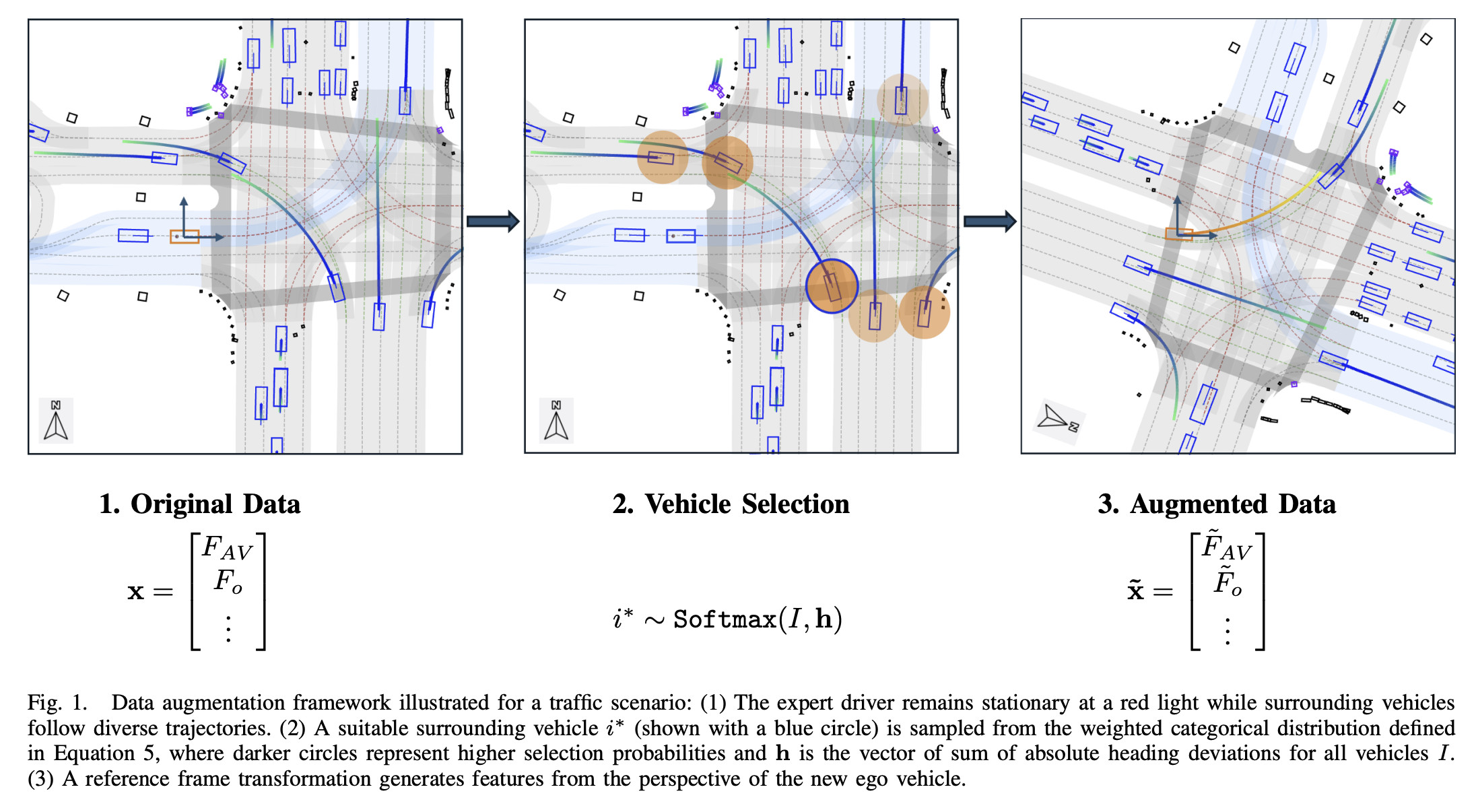
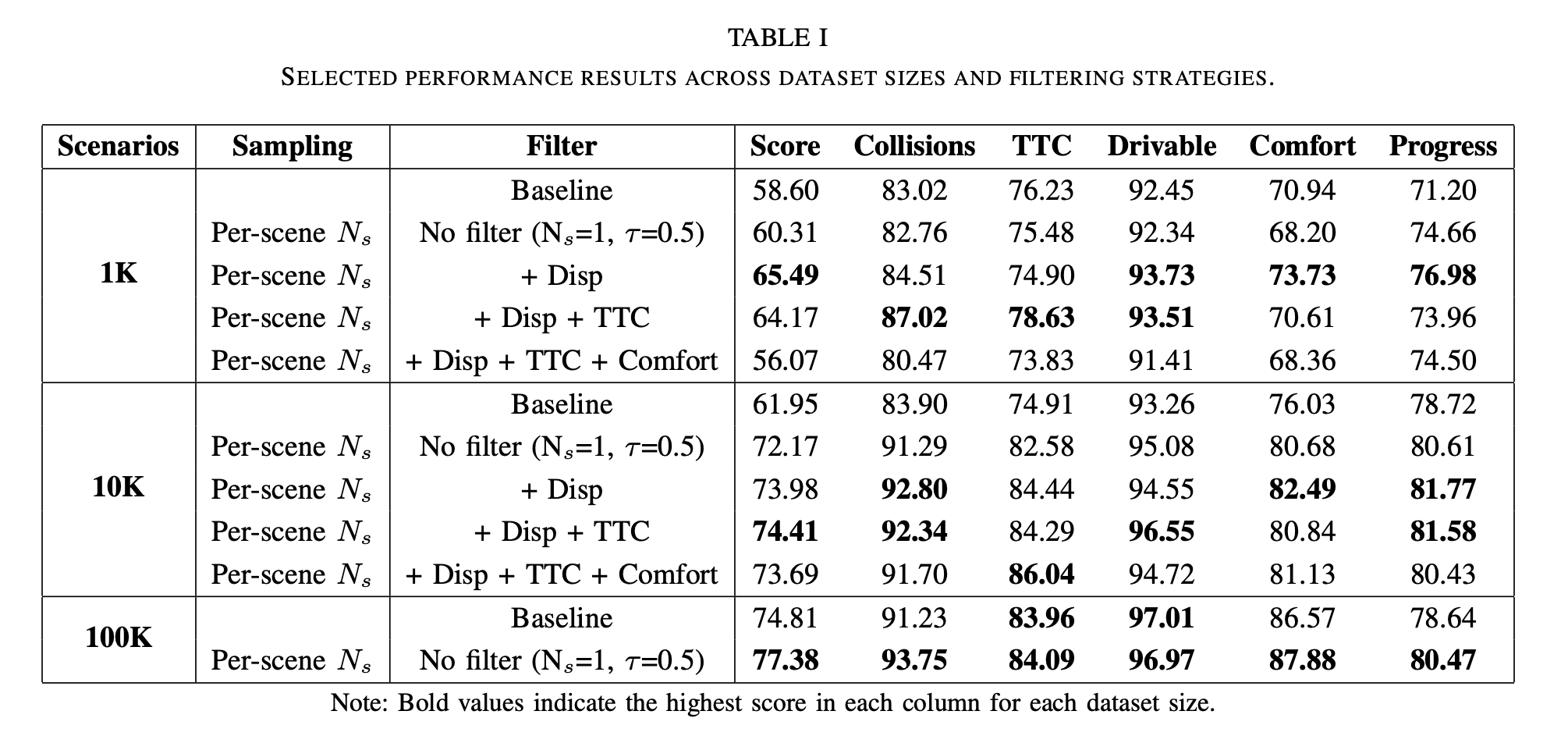
Abstract
Imitation learning is a promising approach for training autonomous vehicles (AV) to navigate complex traffic environments by mimicking expert driver behaviors. However, a major challenge in this paradigm lies in effectively utilizing available driving data, as collecting new data is resource-intensive and often limited in its ability to cover diverse driving scenarios. While existing imitation learning frameworks focus on leveraging expert demonstrations, they often overlook the potential of additional complex driving data from surrounding traffic participants. In this paper, we propose a data augmentation strategy that enhances imitation learning by leveraging the observed trajectories of nearby vehicles, captured through the AV's sensors, as additional expert demonstrations. We introduce a vehicle selection sampling strategy that prioritizes informative and diverse driving behaviors, contributing to a richer and more diverse dataset for training. We evaluate our approach using the state-of-the-art learning-based planning method PLUTO on the nuPlan dataset and demonstrate that our augmentation method leads to improved performance in complex driving scenarios. Specifically, our method reduces collision rates and improves safety metrics compared to the baseline. Notably, even when using only 10% of the original dataset, our method achieves performance comparable to that of the full dataset, with improved collision rates.